import pandas as pd
import numpy as np
import seaborn as sns
df1=pd.DataFrame({
"제품":["사과","딸기","수박"],
"가격":[1800,1500,3000],
"판매량":[24,38,13]})
df1| 제품 | 가격 | 판매량 | |
|---|---|---|---|
| 0 | 사과 | 1800 | 24 |
| 1 | 딸기 | 1500 | 38 |
| 2 | 수박 | 3000 | 13 |
import pandas as pd
import numpy as np
import seaborn as sns
df1=pd.DataFrame({
"제품":["사과","딸기","수박"],
"가격":[1800,1500,3000],
"판매량":[24,38,13]})
df1| 제품 | 가격 | 판매량 | |
|---|---|---|---|
| 0 | 사과 | 1800 | 24 |
| 1 | 딸기 | 1500 | 38 |
| 2 | 수박 | 3000 | 13 |
print(f"과일 가격 평균:{df1["가격"].mean()}, 과일 판매량 평균:{df1["판매량"].mean()}")과일 가격 평균:2100.0, 과일 판매량 평균:25.0df2=pd.read_csv('data/mpg.csv')
df3=df2.copy()
df3.head()| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | category | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| 1 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| 2 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| 4 | audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
df3.rename(columns={"cty":"city","hwy":"highway"},inplace=True)
df3.head()| manufacturer | model | displ | year | cyl | trans | drv | city | highway | fl | category | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| 1 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| 2 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| 4 | audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
df4=pd.read_csv('data/midwest.csv')
df4.head()| PID | county | state | area | poptotal | popdensity | popwhite | popblack | popamerindian | popasian | ... | percollege | percprof | poppovertyknown | percpovertyknown | percbelowpoverty | percchildbelowpovert | percadultpoverty | percelderlypoverty | inmetro | category | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 561 | ADAMS | IL | 0.052 | 66090 | 1270.961540 | 63917 | 1702 | 98 | 249 | ... | 19.631392 | 4.355859 | 63628 | 96.274777 | 13.151443 | 18.011717 | 11.009776 | 12.443812 | 0 | AAR |
| 1 | 562 | ALEXANDER | IL | 0.014 | 10626 | 759.000000 | 7054 | 3496 | 19 | 48 | ... | 11.243308 | 2.870315 | 10529 | 99.087145 | 32.244278 | 45.826514 | 27.385647 | 25.228976 | 0 | LHR |
| 2 | 563 | BOND | IL | 0.022 | 14991 | 681.409091 | 14477 | 429 | 35 | 16 | ... | 17.033819 | 4.488572 | 14235 | 94.956974 | 12.068844 | 14.036061 | 10.852090 | 12.697410 | 0 | AAR |
| 3 | 564 | BOONE | IL | 0.017 | 30806 | 1812.117650 | 29344 | 127 | 46 | 150 | ... | 17.278954 | 4.197800 | 30337 | 98.477569 | 7.209019 | 11.179536 | 5.536013 | 6.217047 | 1 | ALU |
| 4 | 565 | BROWN | IL | 0.018 | 5836 | 324.222222 | 5264 | 547 | 14 | 5 | ... | 14.475999 | 3.367680 | 4815 | 82.505140 | 13.520249 | 13.022889 | 11.143211 | 19.200000 | 0 | AAR |
5 rows × 28 columns
import matplotlib.pyplot as plt
df4.rename(columns={"poptotal":"total","popasian":"asian"},inplace=True)
df4['percent']=df4['asian']/df4['total'] *100
df4['percent'].plot.hist()
plt.title("Total Population")
df4.head()| PID | county | state | area | total | popdensity | popwhite | popblack | popamerindian | asian | ... | percprof | poppovertyknown | percpovertyknown | percbelowpoverty | percchildbelowpovert | percadultpoverty | percelderlypoverty | inmetro | category | percent | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 561 | ADAMS | IL | 0.052 | 66090 | 1270.961540 | 63917 | 1702 | 98 | 249 | ... | 4.355859 | 63628 | 96.274777 | 13.151443 | 18.011717 | 11.009776 | 12.443812 | 0 | AAR | 0.376759 |
| 1 | 562 | ALEXANDER | IL | 0.014 | 10626 | 759.000000 | 7054 | 3496 | 19 | 48 | ... | 2.870315 | 10529 | 99.087145 | 32.244278 | 45.826514 | 27.385647 | 25.228976 | 0 | LHR | 0.451722 |
| 2 | 563 | BOND | IL | 0.022 | 14991 | 681.409091 | 14477 | 429 | 35 | 16 | ... | 4.488572 | 14235 | 94.956974 | 12.068844 | 14.036061 | 10.852090 | 12.697410 | 0 | AAR | 0.106731 |
| 3 | 564 | BOONE | IL | 0.017 | 30806 | 1812.117650 | 29344 | 127 | 46 | 150 | ... | 4.197800 | 30337 | 98.477569 | 7.209019 | 11.179536 | 5.536013 | 6.217047 | 1 | ALU | 0.486918 |
| 4 | 565 | BROWN | IL | 0.018 | 5836 | 324.222222 | 5264 | 547 | 14 | 5 | ... | 3.367680 | 4815 | 82.505140 | 13.520249 | 13.022889 | 11.143211 | 19.200000 | 0 | AAR | 0.085675 |
5 rows × 29 columns
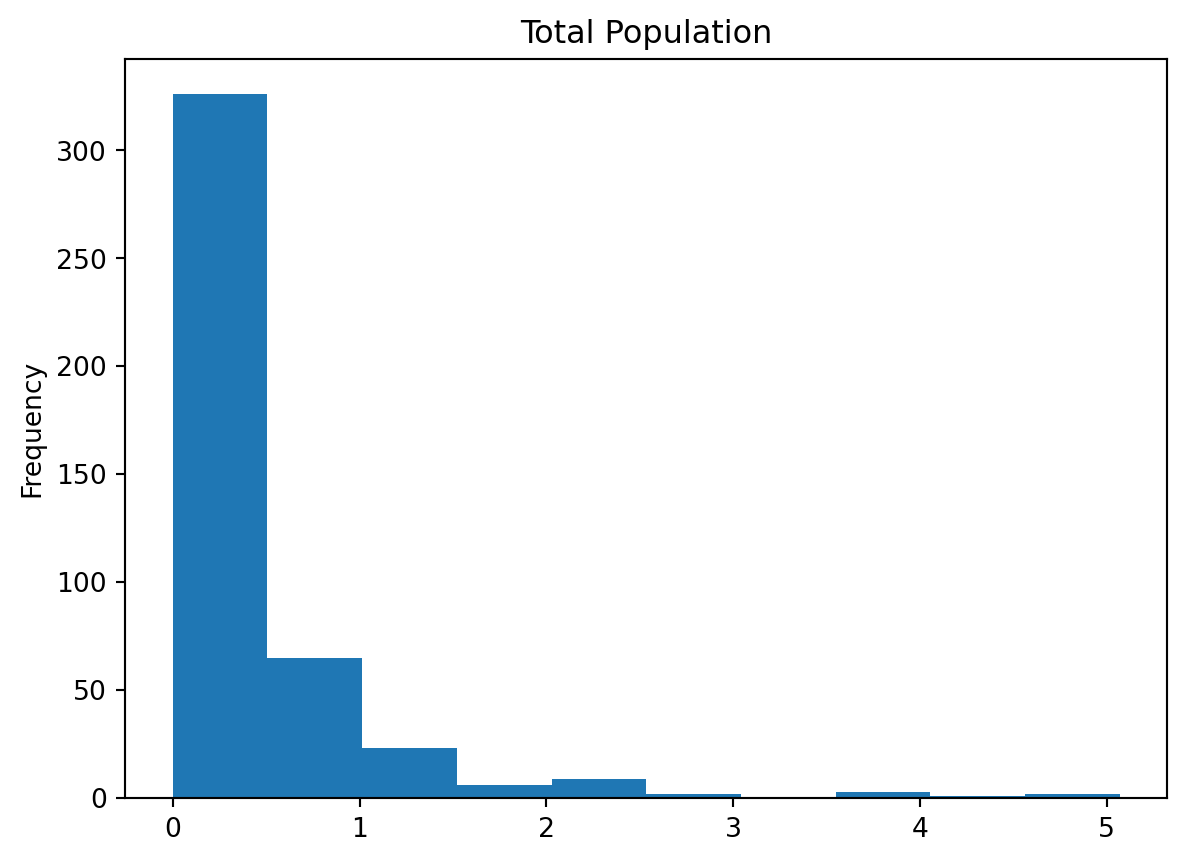
print(f"아시아 인구 백분율 전체 평균: {df4['percent'].mean()}")
df4['large_small']=np.where(df4['percent'].mean()>=df4['percent'],"small","large")
df4.head()아시아 인구 백분율 전체 평균: 0.4872461834357345| PID | county | state | area | total | popdensity | popwhite | popblack | popamerindian | asian | ... | poppovertyknown | percpovertyknown | percbelowpoverty | percchildbelowpovert | percadultpoverty | percelderlypoverty | inmetro | category | percent | large_small | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 561 | ADAMS | IL | 0.052 | 66090 | 1270.961540 | 63917 | 1702 | 98 | 249 | ... | 63628 | 96.274777 | 13.151443 | 18.011717 | 11.009776 | 12.443812 | 0 | AAR | 0.376759 | small |
| 1 | 562 | ALEXANDER | IL | 0.014 | 10626 | 759.000000 | 7054 | 3496 | 19 | 48 | ... | 10529 | 99.087145 | 32.244278 | 45.826514 | 27.385647 | 25.228976 | 0 | LHR | 0.451722 | small |
| 2 | 563 | BOND | IL | 0.022 | 14991 | 681.409091 | 14477 | 429 | 35 | 16 | ... | 14235 | 94.956974 | 12.068844 | 14.036061 | 10.852090 | 12.697410 | 0 | AAR | 0.106731 | small |
| 3 | 564 | BOONE | IL | 0.017 | 30806 | 1812.117650 | 29344 | 127 | 46 | 150 | ... | 30337 | 98.477569 | 7.209019 | 11.179536 | 5.536013 | 6.217047 | 1 | ALU | 0.486918 | small |
| 4 | 565 | BROWN | IL | 0.018 | 5836 | 324.222222 | 5264 | 547 | 14 | 5 | ... | 4815 | 82.505140 | 13.520249 | 13.022889 | 11.143211 | 19.200000 | 0 | AAR | 0.085675 | small |
5 rows × 30 columns
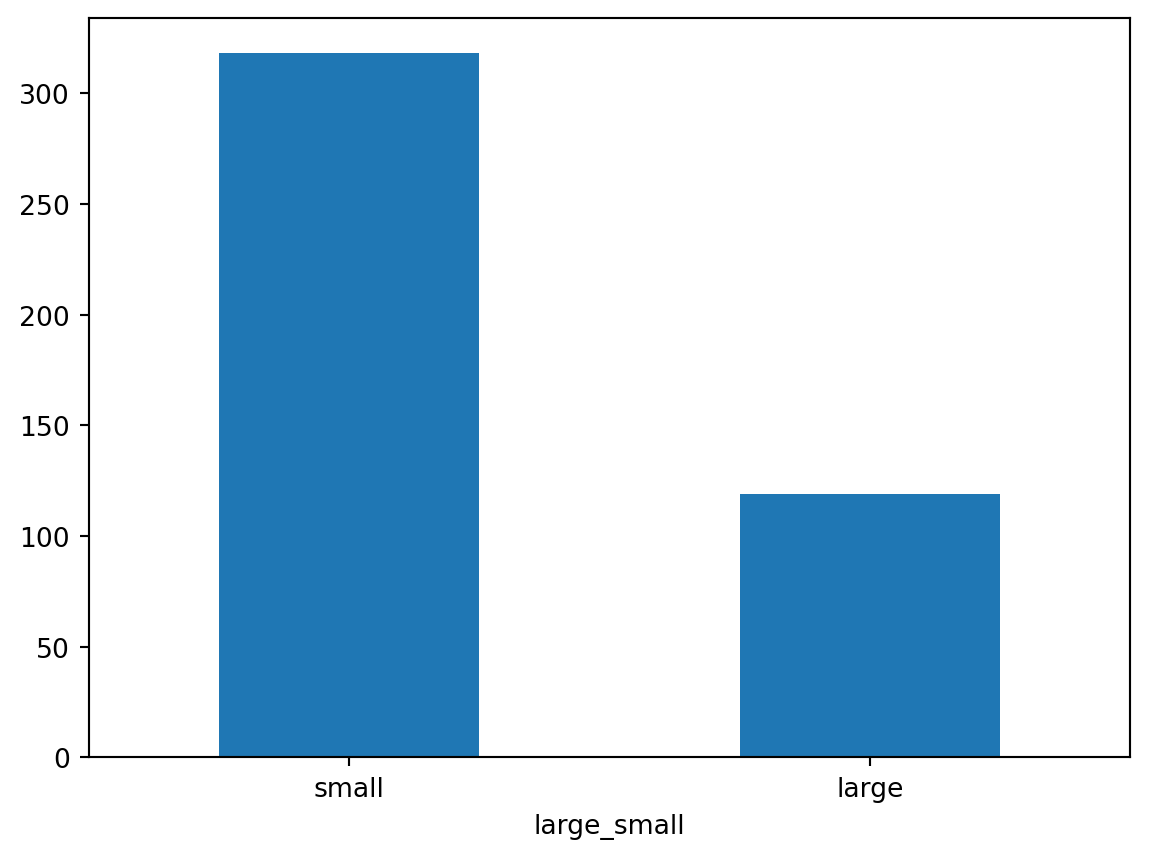
df4_count=df4["large_small"].value_counts()
df4_countlarge_small
small 318
large 119
Name: count, dtype: int64df4_count.plot.bar(rot=0)