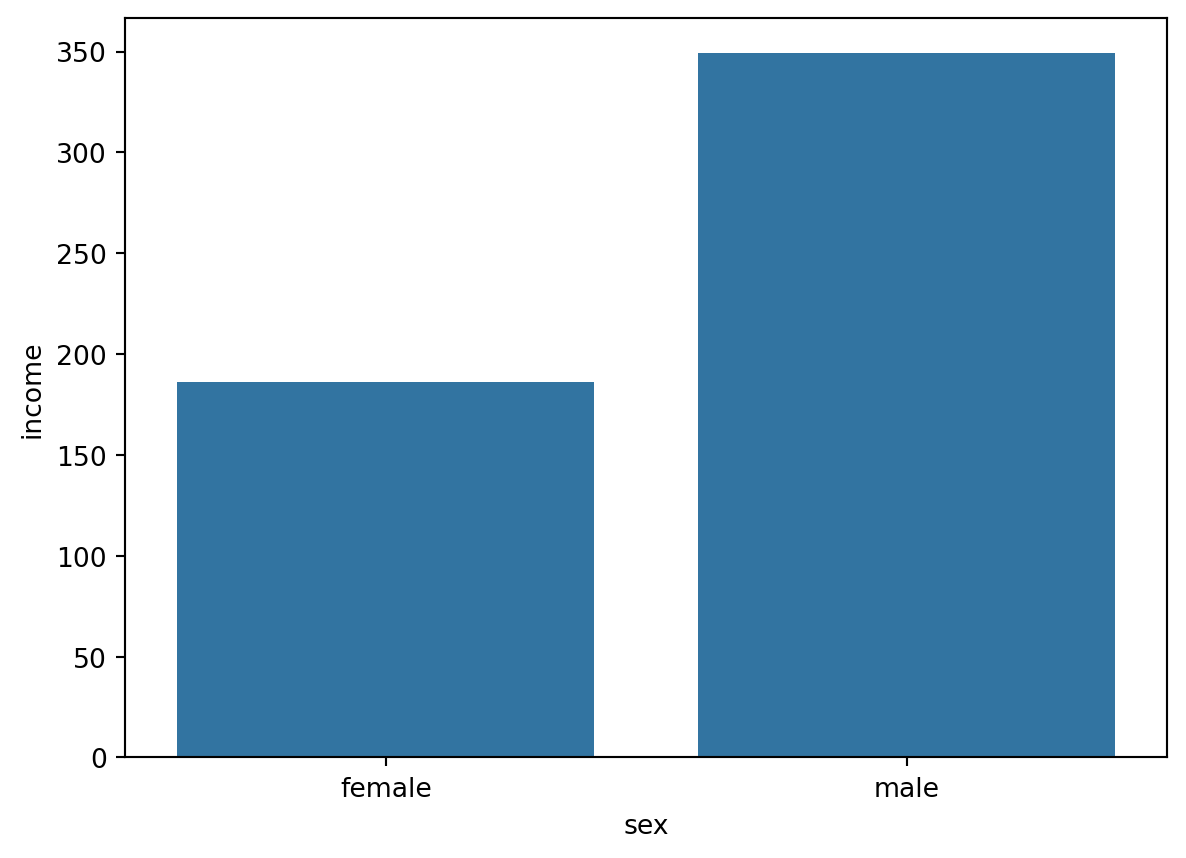
# 월급 전처리 & 평균 , 시각화sex_income=welfare.dropna(subset="income").groupby("sex",as_index=False)[["income"]].mean() sns.barplot(data=sex_income, x="sex", y="income")plt.show()
=======
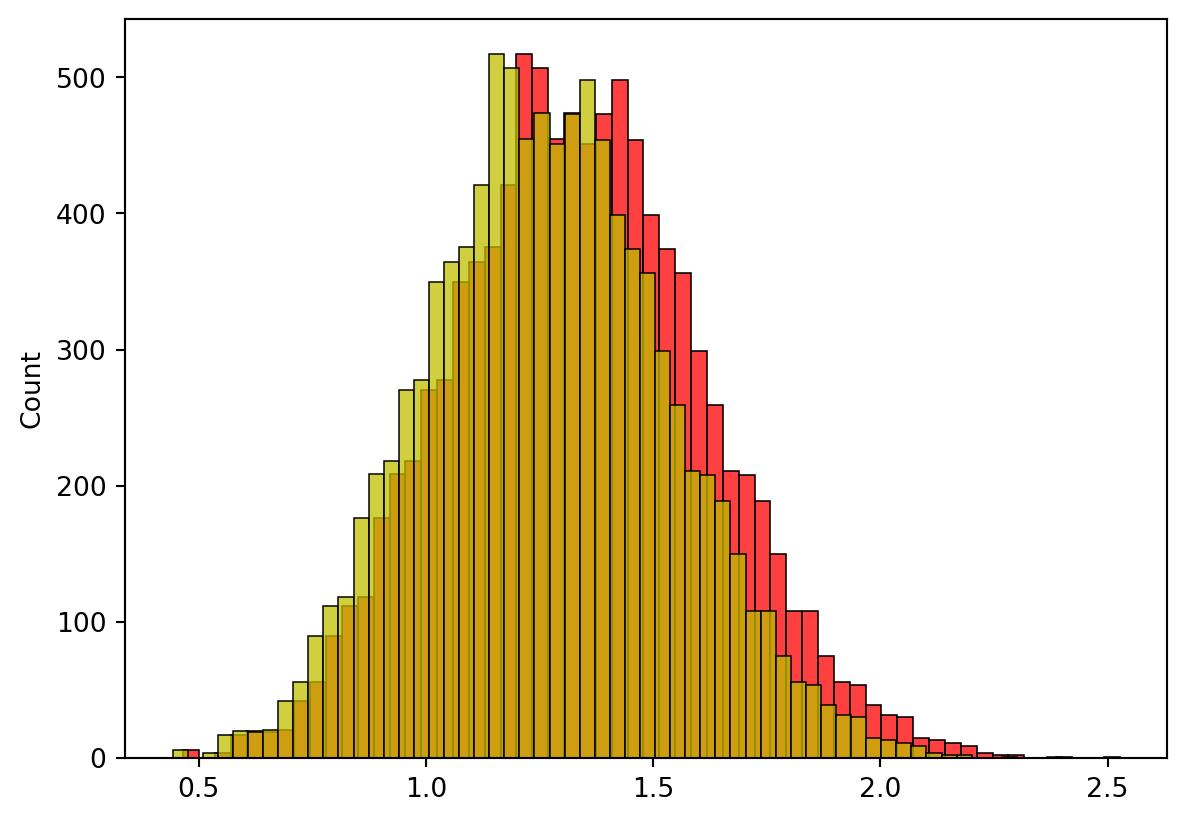
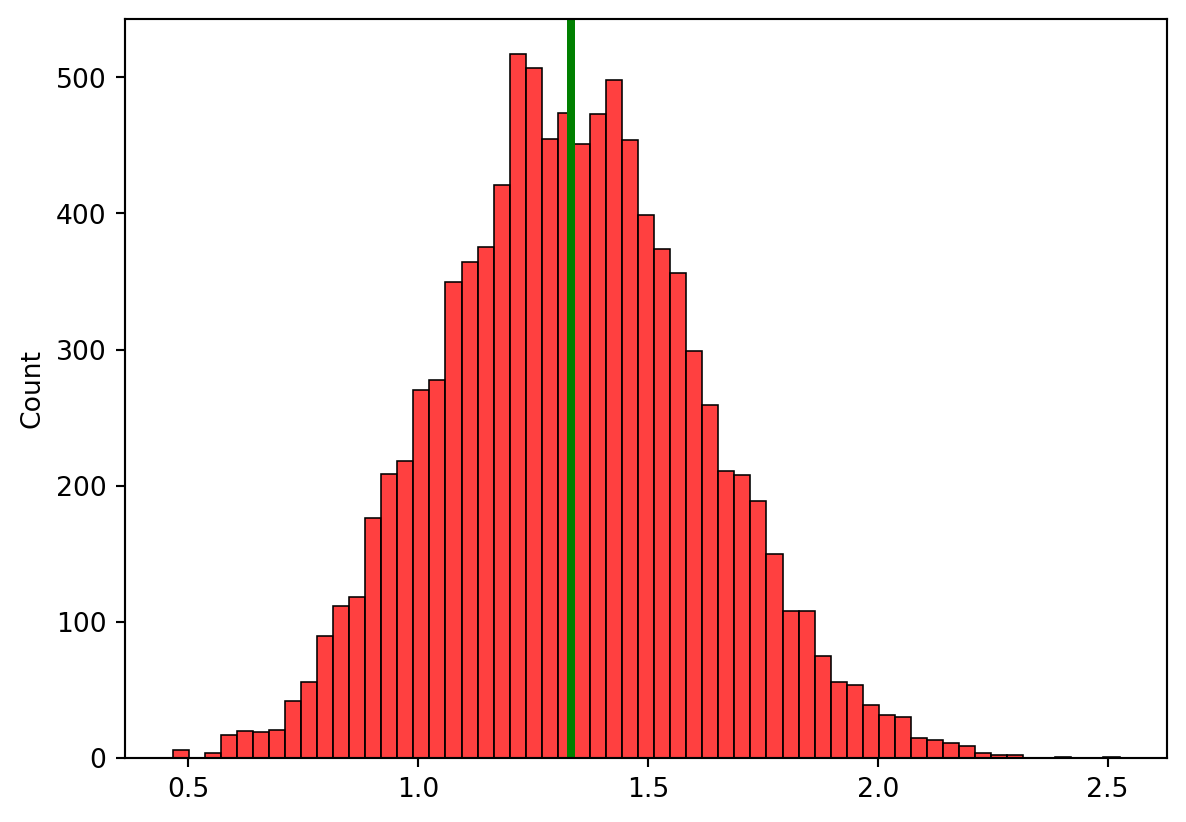
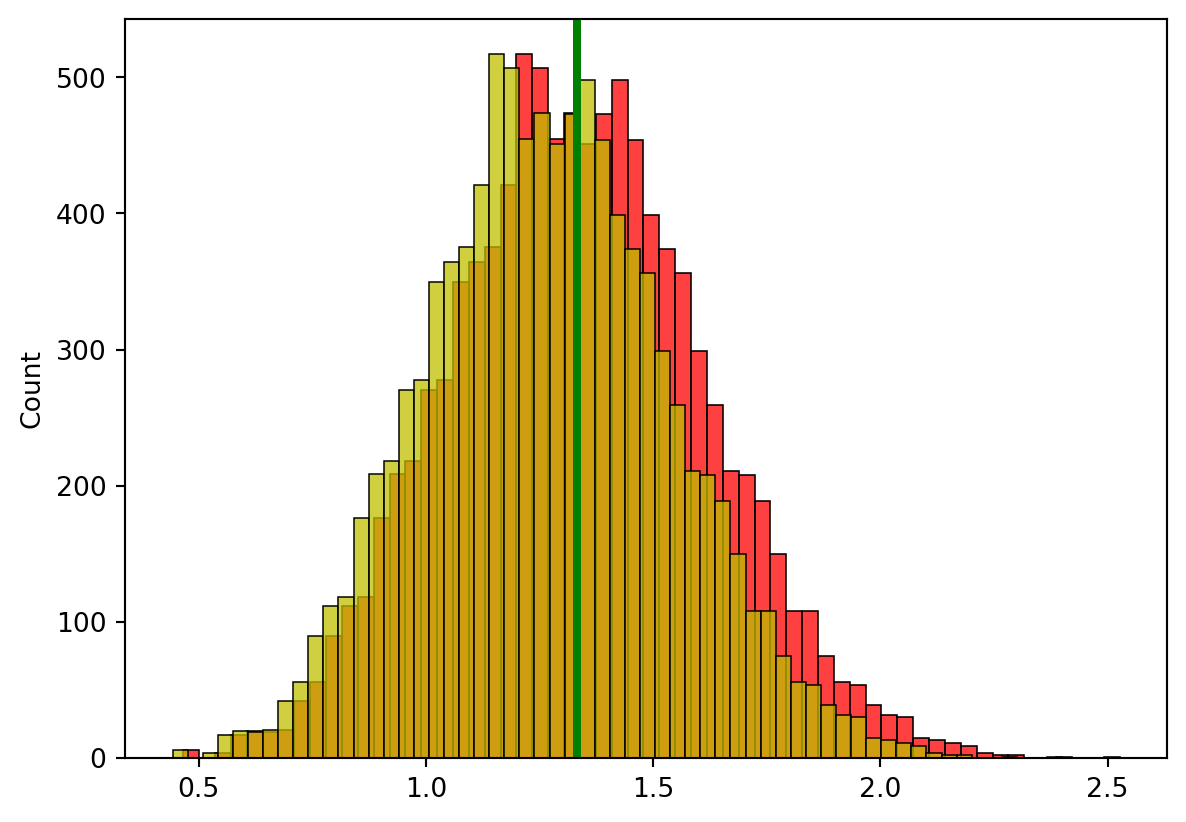
표본 분산 계산 시 왜 n-1로 나누는지 알아보도록 하겠습니다. 균일분포 (3, 7)에서 20개의 표본을 뽑아서 분산을 2가지 방법으로 추정해보세요.
1. n-1로 나눈 것을 s_2, n으로 나눈 것을 k_2로 정의하고, s_2의 분포와 k_2의 분포를 그려주세요! (10000개 사용)
import numpy as np import pandas as pdimport matplotlib.pyplot as plt import seaborn as sns s_2=[]k_2=[]for i inrange(10000): a=np.random.uniform(3,7,20) b=sum((a-a.mean())**2) c_1=b/(len(a)-1) c=b/(len(a)) s_2.append(c_1) k_2.append(c)sns.histplot(data=s_2, color="red")sns.histplot(data=k_2, color="y")plt.show()
>>>>>>> 6cbbb7eade37dee30b9807f3594b0c1fd3e6305a
<<<<<<< HEAD
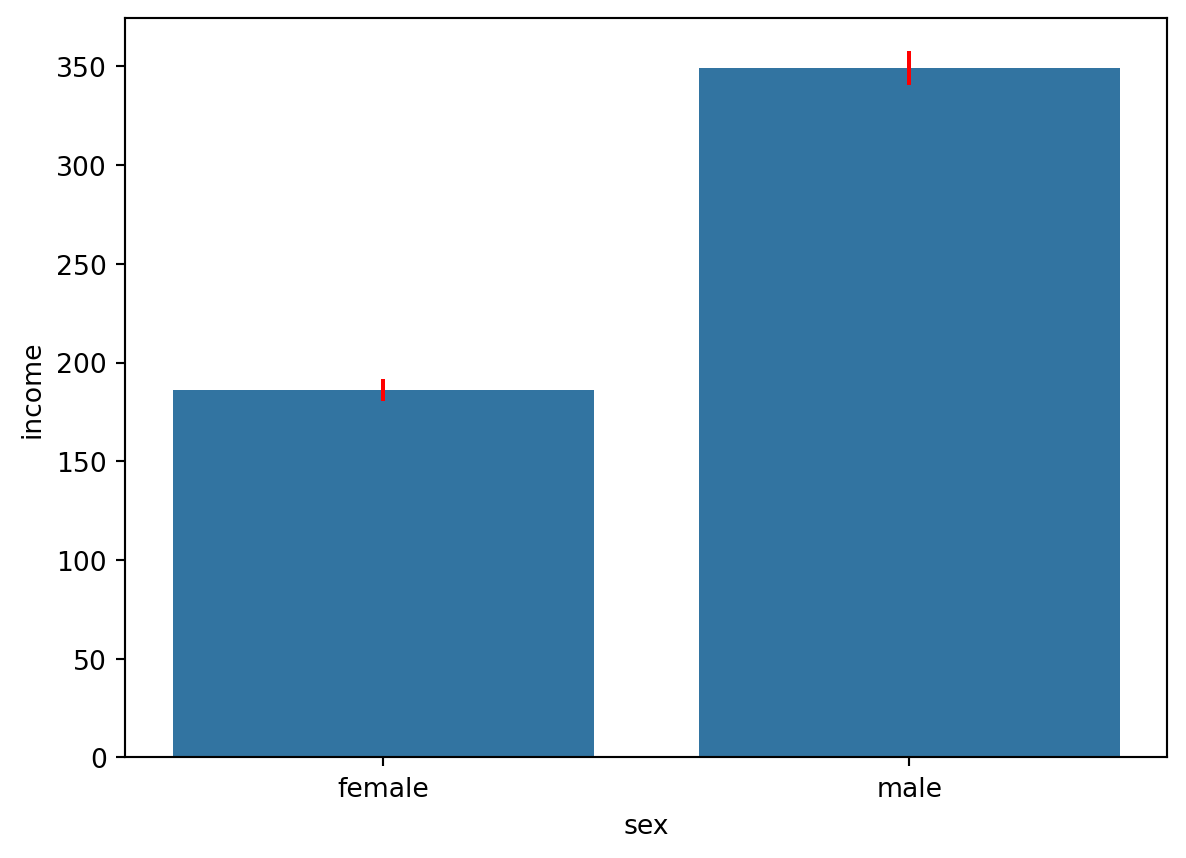
각 성별 95% 신뢰구간 계산후 그리기. norm.ppf() 사용해서 그릴 것. 모분산은 표본 분산을 사용해서 추정
from scipy.stats import*all_income=welfare.dropna(subset="income")f_income=all_income.loc[all_income["sex"]=="female","income"]m_income=all_income.loc[all_income["sex"]=="male","income"]f_mean=f_income.mean()m_mean=m_income.mean()f_std=f_income.std()m_std=m_income.std()f_n =len(f_income)m_n =len(m_income)