표본 분산 계산 시 왜 n-1로 나누는지 알아보도록 하겠습니다. 균일분포 (3, 7)에서 20개의 표본을 뽑아서 분산을 2가지 방법으로 추정해보세요.
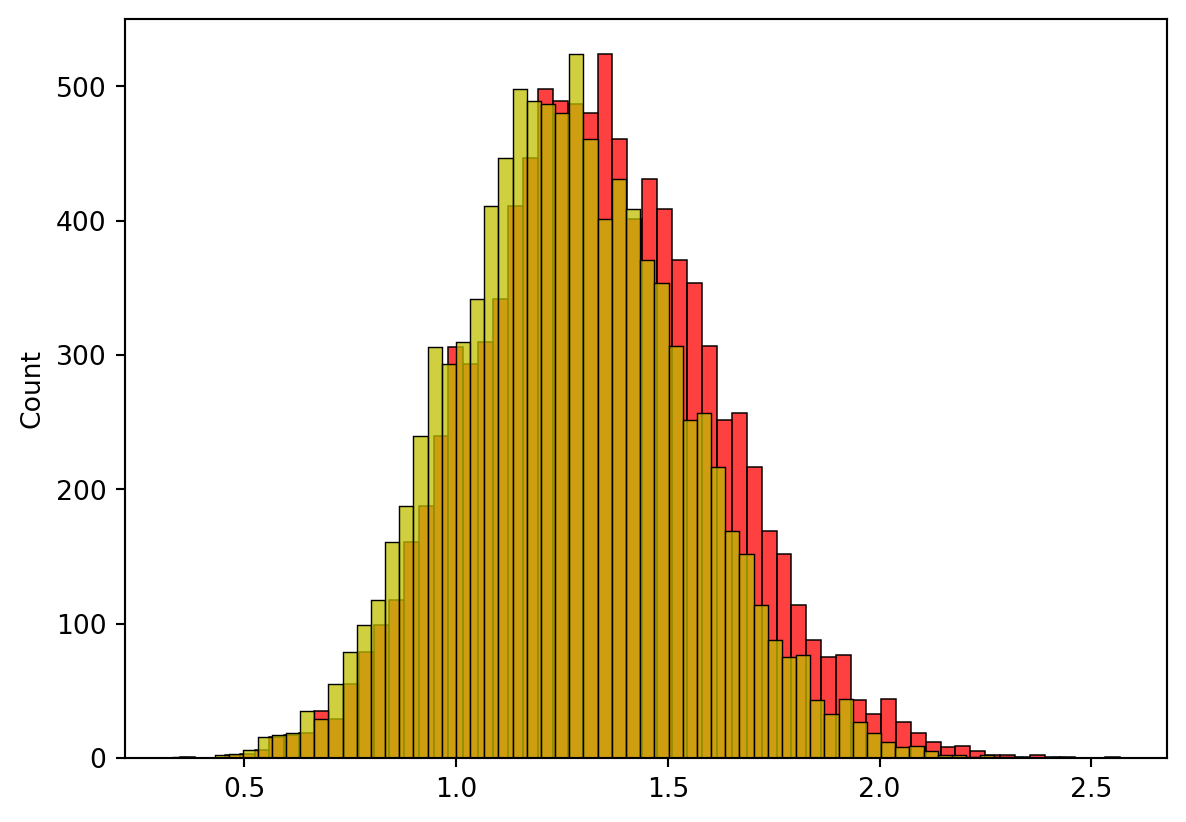
1. n-1로 나눈 것을 s_2, n으로 나눈 것을 k_2로 정의하고, s_2의 분포와 k_2의 분포를 그려주세요! (10000개 사용)
import numpy as np import pandas as pdimport matplotlib.pyplot as plt import seaborn as sns from scipy.stats import uniforms_2=[]k_2=[]for i inrange(10000): a=uniform.rvs(size=20, loc=3, scale=4) b=sum((a-a.mean())**2) c_1= b/(len(a)-1) c = b/(len(a)) s_2.append(c_1) k_2.append(c)sns.histplot(data=s_2, color="red")sns.histplot(data=k_2, color="y")plt.show()
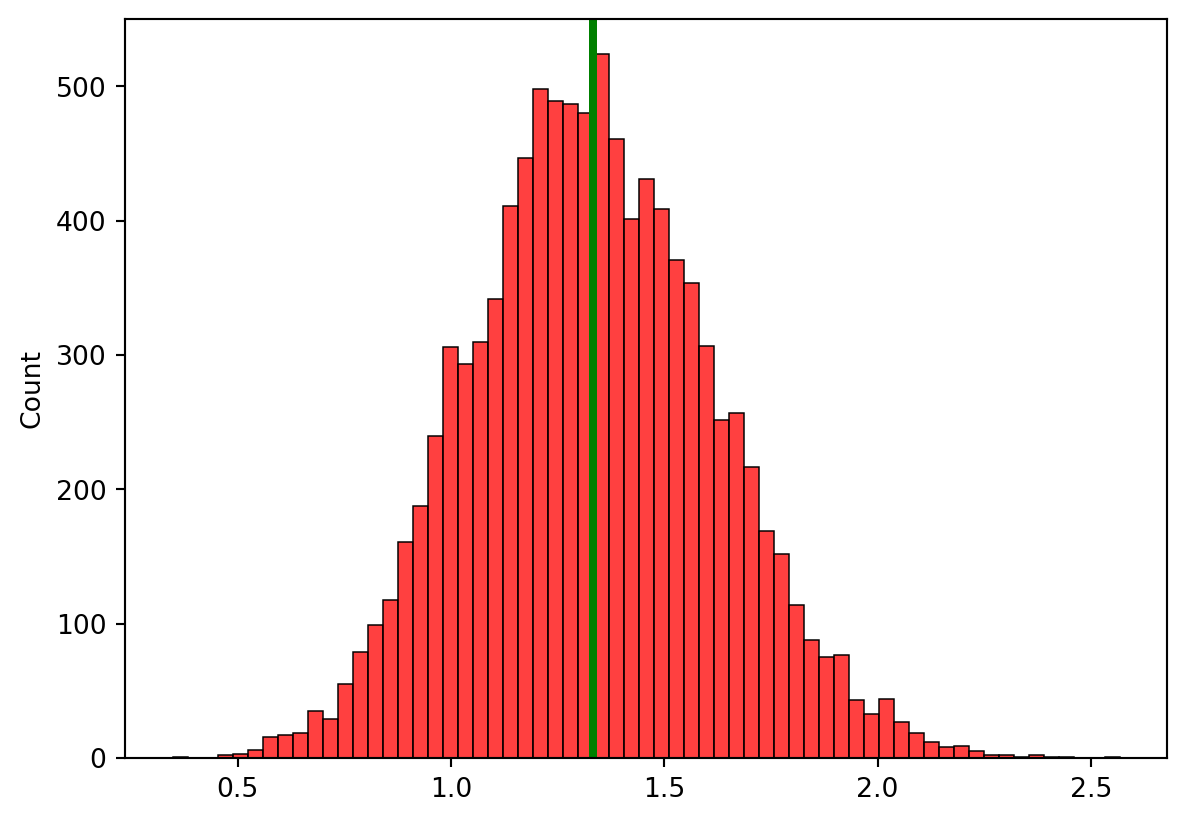
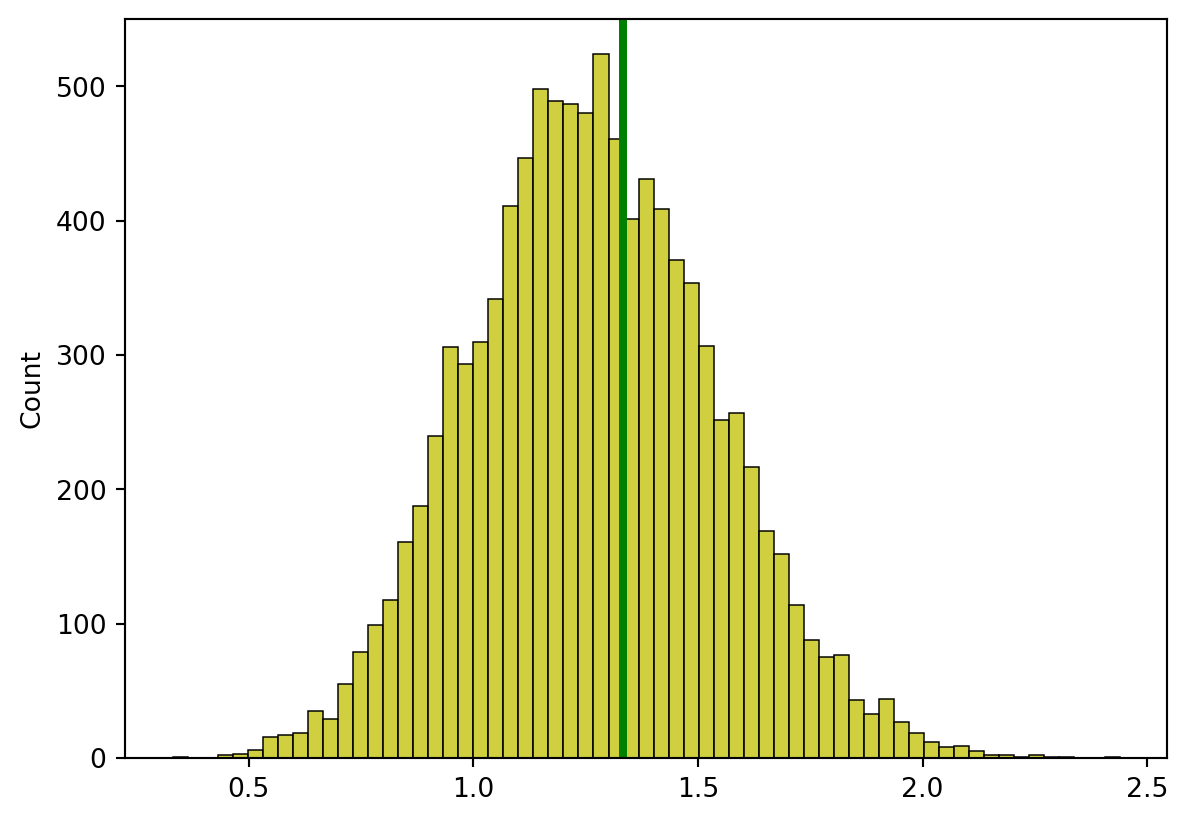
2. 각 분포 그래프에 모분산의 위치에 녹색 막대를 그려주세요.
var=((7-3)**2)/12plt.axvline(var, color ='green', linestyle ='-', linewidth =3)sns.histplot(data=s_2, color="red")plt.show()print("n-1로 나눈 것")
n-1로 나눈 것
plt.axvline(var, color ='green', linestyle ='-', linewidth =3)sns.histplot(data=k_2, color="y")plt.show()print("n으로 나눈 것")
n으로 나눈 것
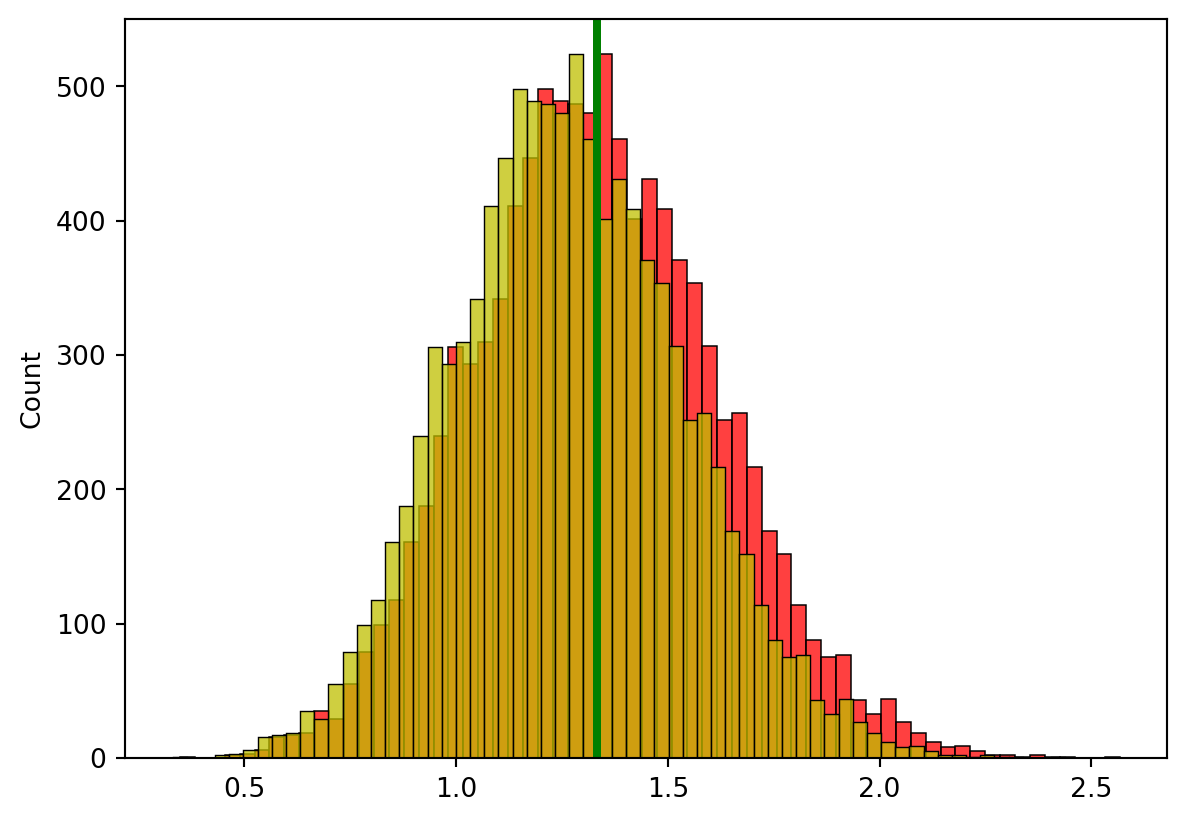
3. 결과를 살펴보고, 왜 n-1로 나눈 것을 분산을 추정하는 지표로
사용하는 것이 타당한지 써주세요!
plt.axvline(var, color ='green', linestyle ='-', linewidth =3)sns.histplot(data=s_2, color="red")sns.histplot(data=k_2, color="y")plt.show()